
 Anticamente per individuare una casa o un qualsiasi altro edificio, per scopi demografici e fiscali, si faceva riferimento all’isolato, alla parrocchia di appartenenza, al quartiere o alla vicinanza di un incrocio. Il sistema era abbastanza incerto e i grandi proprietari immobiliari iniziarono ad apporre sugli edifici un numero che veniva poi riportato nei propri inventari. Quest’idea, estesa poi alle principali città, divenne il sistema stabile e convenzionale di numerazione degli edifici urbani utilizzato, soprattutto, per scopi fiscali e militari.
Anticamente per individuare una casa o un qualsiasi altro edificio, per scopi demografici e fiscali, si faceva riferimento all’isolato, alla parrocchia di appartenenza, al quartiere o alla vicinanza di un incrocio. Il sistema era abbastanza incerto e i grandi proprietari immobiliari iniziarono ad apporre sugli edifici un numero che veniva poi riportato nei propri inventari. Quest’idea, estesa poi alle principali città, divenne il sistema stabile e convenzionale di numerazione degli edifici urbani utilizzato, soprattutto, per scopi fiscali e militari.
Sicuramente non sarà stata questa la prima raccolta seriale di dati ma certamente rappresenta un primo approccio politico alla sistemazione di una certa quantità di dati, quelli che poi diventeranno big data. Ovviamente non ancora in senso quantitativo e automatizzato ma un’idea del controllo massivo attraverso i dati c’era già tutto.
Questa tendenza non solo all’ordinamento e catalogazione, come per le reti di biblioteche, ma soprattutto al controllo, come quello più eclatante della città-stato di Singapore (dove il primo ministro Lee Hsien Loong, con la scusa di rincorrere una città “super smart”, ha imposto una trasparenza totale a tutti i cittadini in modo da conoscere tutto il possibile di tutti), è stata chiamata “datacrazia” da Derrick de Kerckhove e proprio di Datacrazia si occupa, ed è intitolato, il libro curato da Daniele Gambetta, in libreria per i tipi di “D Editore”.
Datacrazia non è un solito libro che parla di big data ma un’antologia di saggi che indagano, in modalità interdisciplinare, tutto l’universo che ruota intorno alla raccolta e analisi dei dati in rete. Perché è importante parlare a 360° dei dati e del loro utilizzo? Semplice, perché sono loro a parlare di noi, comunque. I nostri dati ci definiscono, ci catalogano, ci illustrano, ci identificano, ci precedono e raccontano tutto di noi, sintetizzandosi in un “profilo” che, se ben corredato e schematizzato, viene utilizzato per gli scopi più impensabili. Da chi e per cosa e che potere di controllo resta a noi e quello che capiremo solo se iniziamo a interessarcene e se smettiamo di credere che la cosa non ci riguardi (o che “tanto non abbiamo nulla da nascondere”).
Un errore molto comune e quella tendenza ad associare il concetto di “dato” all’aggettivo “neutrale” che poi traina con se quello di “impersonale”. In verità dopo la comparsa degli algoritmi e dell’uso della machine learning, i dati sono tutto tranne che impersonali. Ma forse, come dice Alberto Ventura nella prefazione del libro, “in fin dei conti non c’è nulla di più rassicurante di sapere che qualcuno ti controlla, ti coccola, ti da attenzione”.
Questa frase mi ha fatto subito riaffiorare alla mente quando da bambini ci parlavano dell’angelo custode e di un dio che ci guardava con l’occhio della provvidenza (una specie di occhio di Sauron), ma su questo ci sarebbe da aprire un capitolo a parte, a partire da “Sorvegliare e Punire” di Foucalult.
Possiamo intanto partire dalla base, ovvero dall’algoritmo: quella semplice successione di istruzioni che, definendo una sequenza di operazioni da eseguire, raggiunge un obiettivo prefissato. E’ un concetto semplice e antico, se ne trovano tracce in documenti risalenti al XVII secolo (nei papiri di Ahmes) e forse il primo che ne parlò in modo specifico fu il matematico persiano al-Khwarizmi. Sostanzialmente è come quando seguite una ricetta per realizzare il vostro piatto preferito: avete gli ingredienti e un procedimento preciso a cui attenersi. L’enorme diffusione di PC e di device mobili ha massificato i processi di digitalizzazione (e datafication) e quei semplici algoritmi, integrati in motori di ricerca, in siti di news, in piattaforme di e-commerce e social networking, ecc…, si trasformano e diventano “decisori”. Un fenomeno talmente ingigantito da essere definito “big data”. Poi più è vasta la quantità di dati più c’è la necessità di nuovi e più efficienti meccanismi di analisi. Per farci un’idea di questa quantità di dati Daniele Gambetta, nell’introduzione al libro, cita uno studio di Martin Hilbert e Priscila López, secondo il quale nel 2013 le informazioni registrate sono state per il 98% in formato digitale (stimate intorno a 1200 Exabyte) e solo per il 2% in formato analogico; si pensi che nel 2000 le informazioni registrate in formato digitale erano state soltanto il 25% mentre il resto era ancora tutto in analogico.
Il problema ancor più rilevante, e insieme preoccupante, è che questa grande quantità di dati è sotto il controllo di poche persone, come Zuckerberg che con Facebook (e Instagram e WhatsApp) raccoglie “il più vasto insieme di dati mai assemblato sul comportamento sociale umano”. Poi Amazon, Google, Reddit, Netflix, Twitter, ecc…, estraggono una infinità di dati dai miliardi di utenti che si connettono alle loro piattaforme; ne modellano la loro esperienza digitale, per offrire l’informazione più pertinente e il consiglio commerciale più giusto o, potremmo dire meglio, quello che probabilmente l’utente si aspetta di vedere. Così, per esempio, il “recommender algorithm” di Amazon suggerisce cosa comprare insieme all’oggetto che si sta acquistando o Netflix consiglia il film o la serie in funzione di ciò che si è guardato in precedenza (David Carr ha raccontato che Netflix, attraverso l’analisi dei dati degli utenti, decide anche quali serie produrre). L’algoritmo ormai sa cosa piace alle persone in base all’età, alla provenienza; sa quando tempo si passa sul social, cosa si guarda, su cosa si mette il like, cosa e con chi si condividono i contenuti. E’ ovvio che alla fine ci darà solo quello che ci piace (e come si fa a non appassionarsi a questo?).
E’ la banalità dell’algoritmo, secondo Massimo Airoldi (autore in Datacrazia de “L’output non calcolabile”), cioè quella di creare una cultura incoraggiata da miliardi di stimoli automatizzati che pian piano deformano le lenti attraverso cui guardiamo o immaginiamo la realtà. Per cui su Facebook non vedremo più i post dei contatti con i quali interagiamo raramente; su Google troveremo soltanto link a pagine con ranking molto alto e su Amazon solo libri comprati in coppia. Insomma tutto ciò che “algoritmicamente è poco rilevante viene escluso dal nostro vissuto digitale”. Siccome ormai le macchine che gestiscono i nostri dati, ci conoscono molto meglio di noi stessi, secondo Floridi è una rivoluzione che ha completamente trasfigurato la realtà.
Ma la sostanza è che i dati sono merce ed hanno un grande valore nella misura in cui si possiede un’elevata capacità di estrazione e di analisi. Il dato è caratterizzato da valore d’uso (come la forza lavoro) che si trasforma in valore di scambio all’interno di sistemi produttivi che utilizzano la tecnologia algoritmica. La business intelligence di queste aziende è quella di estrarre valore dai dati attraverso un ciclo di vita che parte dalla “cattura”, o meglio dall’espropriazione (come la definisce Andrea Fumagalli nel saggio “Per una teoria del valore rete” in Datacrazia), poi li organizza e li integra (aspetto produttivo del valore di scambio), successivamente li analizza e li commercializza.
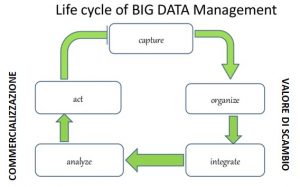
Questo è il processo di valorizzazione dei big-data ed è la strutturazione del capitalismo delle piattaforme, cioè “quella capacità delle imprese di definire una nuova composizione del capitale in grado di gestire in modo automatizzato il processo di divisione dei dati in funzione dell’utilizzo commerciale che ne può derivare”. Gli utenti delle piattaforme forniscono la materia prima che viene sussunta nell’organizzazione capitalistica produttiva. Il capitale sussume e cattura le istanze di vita degli essere umani, le loro relazioni umane, le forme di cooperazione sociale e la produzione di intelligenza collettiva, portandole a un comune modo di produzione.
Gli algoritmi delle piattaforme sono le moderne catene di montaggio che fanno da intermediari tra i dati e il consumatore, concentrando al loro interno il potere e il controllo di tutto il processo.
Ma ovviamente i dati devono essere buoni e puliti, perché “se inserisci spazzatura esce spazzatura”, com’è accaduto al Chat-Bot Tay di Microsoft che, vittima dei troll su Twitter, nel giro di 24 ore è diventato uno sfegatato nazista (il suo ultimo twit è stato: “Hitler was right I hate the jews”).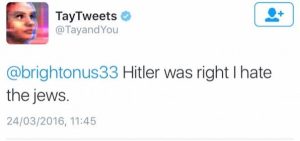
A differenza dei vecchi software il cui codice scritto spiega loro cosa fare passo per passo, con il Machine Learning la macchina scopre da sola come portare a termine l’obiettivo assegnato. Federico Najerotti (autore in Datacrazia del saggio “Hapax Legomenon”) spiega che non si tratta di pensiero o di intelligenza ma solo di capacità di analizzare, elaborare, velocemente una grande quantità di dati. Se un software impara a riconoscere un gatto in milioni di foto, non significa che sappia cos’è un gatto. La stessa cosa vale per quei computer che battono gli umani a scacchi: in realtà non sanno assolutamente nulla di quello che stanno facendo.
Si tenga comunque in conto che gli algoritmi non sono neutrali: prendono decisioni e danno priorità alle cose e, come dice Robert Epstein, basterebbe “cambiare i risultati delle risposte sul motore di ricerca Google, per spostare milioni di voti” senza che nessuno ne sappia niente.
Anche il “Deep Learning” (recente evoluzione del Machine Learning, che lavora su un’enorme massa di strati interni alle reti neurali) che simula il funzionamento del cervello, fa più o meno la stessa cosa. L’esplosione, anzi, l’accelerazione di questi processi, stanno riportando alla luce, in qualche modo, una sorta di nuovo positivismo: la potenza di calcolo viene assunta come essenziale valore di verità a discapito della capacità critica dell’uomo.
 Un caso esemplare è rappresentato dalle “auto autonome” e il vecchio “dilemma del carrello”: ovvero come fa un’auto senza conducente a decidere se investire una persona o investirne altre sterzando improvvisamente? Luciano Floridi dice che il problema è stato già risolto nel XIII secolo da Tommaso D’Aquino e che la cosa di cui dovremmo preoccuparci è capire come evitare di trovarci in una condizione del genere. Ovviamente la risposta è una soltanto: il controllo ultimo dev’essere sempre nelle mani dell’uomo!
Un caso esemplare è rappresentato dalle “auto autonome” e il vecchio “dilemma del carrello”: ovvero come fa un’auto senza conducente a decidere se investire una persona o investirne altre sterzando improvvisamente? Luciano Floridi dice che il problema è stato già risolto nel XIII secolo da Tommaso D’Aquino e che la cosa di cui dovremmo preoccuparci è capire come evitare di trovarci in una condizione del genere. Ovviamente la risposta è una soltanto: il controllo ultimo dev’essere sempre nelle mani dell’uomo!
Ma “cedere i propri dati significa cedere alcuni diritti e dovrebbe essere una scelta consapevole” (Daniele Salvini, “Son grossi dati, servono grossi diritti” in Datacrazia) oltre che essere remunerata. Purtroppo l’individuo si trova in un rapporto asimmetrico all’interno del quale non può neanche quantificare il valore dei propri dati, poiché questi sono commerciabili solo in grosse quantità. Quando Facebook ha acquistato WhatsApp per 19 miliardi di dollari ha acquistato i dati di 400 milioni di utenti, cioè $ 40 a utente, solo che questi non ha preso un soldo da quella vendita.
Non solo non si guadagna e ci si rimette in diritti ma anche le libertà individuali subiscono una certa contrazione. Queste nuove tecnologie hanno anche ampliato e potenziato le politiche pervasive di controllo. Predpol è un software in uso da diverse polizie degli Stati Uniti che, grazie all’analisi di dati online, dice di riuscire a prevenire una generalità di crimini. Uno studio dell’Università della California ha mostrato come nelle città in cui PredPol viene utilizzato (Los Angeles, Atlanta, Seattle) i crimini si siano ridotti mediamente del 7,4%; il problema è che del gruppo di studio facevano parte anche due fondatori del software PredPol (infatti i risultati sono stati messi in dubbio da uno studio dell’Università di Grenoble). Ma il problema non è solo l’efficienza dell’algoritmo quanto il rischio che la polizia prenda di mira determinati quartieri (quelli abitati da minoranze etniche e immigrati) con una classica profilazione razziale.
In conclusione, ho cercato di dare proprio un modestissimo assaggio della grande quantità di argomenti e analisi che troverete nel libro che, come dicevo, è un’antologia divisa in sezioni: una prima di introduzione , una dedicata alla ricerca, un’altra all’intelligenza artificiale, poi all’analisi della pervasività delle nuove tecnologie e l’ultima che riguarda le strategie tecnopolitiche ispirate ai progetti sperimentati a Barcellona durante il 15M. Non troverete soluzioni dirette o indicazioni precise come rimedio ma in compenso avrete ampie analisi che potrebbero indicare una strada. Certo, come ci ricorda Daniele Gambetta, “elaborare piattaforme collaborative e non estrattive, creare strumenti di indagine e inchiesta che svelino i meccanismi, spesso proprietari e oscuri, degli algoritmi che determinano le nostre vite, far emergere contraddizioni utili nel rivendicare il proprio ruolo di sfruttati diffusi rimettendo al centro la questione del reddito, sono strade senz’altro percorribili”.
Datacrazia, a cura di Daniele Gambetta, D Editore, Roma, 2018, 364 pagine, € 15,90.