
 Non è strano e neanche insolito che le applicazioni che fanno applicare filtri alle proprie foto sono tra le più scaricate. Poi se son fatte bene e il filtro è accattivante il successo è assicurato.
Non è strano e neanche insolito che le applicazioni che fanno applicare filtri alle proprie foto sono tra le più scaricate. Poi se son fatte bene e il filtro è accattivante il successo è assicurato.
E’ proprio quello che è successo a FaceApp: invecchiarsi all’improvviso ha intrigato tutti, anche molti Vip che, come al solito, hanno tirato la volata all’app. Filtri del genere ce n’erano già ma il miglioramento software ha fatto davvero la differenza. In poco tempo i social sono stati invasi da circa 8 milioni di facce invecchiate.
Proprietaria dell’applicazione è la società russa Wireless Lab di Yaroslav Goncharov, ex manager di Yandex (il Google russo), che l’ha lanciata un paio di anni fa redendola disponibile sugli store in versione gratuita (ma bisogna passare a quella “Pro” per utilizzare tutte le funzioni disponibili).
Come tutte le app chiede l’accesso alle foto dello smartphone ma, come spiegato da Wired, non dice che i dati vengono inviati ai propri server, dove praticamente avviene la modifica, e qui conservati per un tempo non definito, prima di essere rispediti indietro allo smartphone di partenza.
Alle richieste di spiegazioni Wireless Lab ha risposto che i dati restano sui server per il tempo necessario all’elaborazione per poi essere cancellati e che nessun dato resta in territotio russo e che, in fondo, l’utente può sempre chiedere la cancellazione (anche se il procedimento è piuttosto complicato).
Alla parola “territorio russo” saltano tutti sulla sedia e si allarmano, perchè nell’immaginario collettivo (creato in anni e anni di perseveranza americana) è la terra dei cattivi per antonomasia: quella degli hacker che rubano informazioni e manipolano anche le elezioni (peccato che a beneficiarne è stato proprio il più amato degli americani)… Tutto regolare e funzionale alla logica dell’americano medio, se non fosse per un piccolo particolare, che i server della Wireless Lab non sono in Russia ma su server in cloud di Amazon e di Google.
L’eco che arriva anche sulla stampa nostrana è lo stesso partito dalle preoccupazioni di alcuni senatori USA che hanno invitato tutti a disinstallare l’app perchè, si sa, la parola “russo” fa effetto anche da sola. Ma non è che FaceApp sia proprio il male assoluto; in fondo tutte le applicazioni di questo tipo, alla fine, fanno più o meno le stesse cose. Anzi il diabolico trio di Zuckeberg (Facebook, Instagram e WhatsApp) fa anche peggio, per non parlare poi di quello che Google fa con i nostri dati.
C’è differenza? Non molto. A parte il fatto che alcune app descrivono più o meno dettagliatamente dove si trovano i nostri dati e un po’ meno cosa si fa con essi, per il resto sappiamo bene che è meglio non fidarci e non usarle.
Ma è, come si dice dalle mie parti, “acqua santa persa” perchè non conosco molte persone che si preoccupano di leggersi tutto prima di installare un’app e soprattutto si rifiutino di autorizzarle a manipolare tutto sul nostro smartphone: dalla rubrica all’archivio, dalla fotocamera al microfono.
E quindi? Tanto rumore per nulla?
Per nulla proprio no, ma l’importante che un utente completamente immerso tra WhatsApp, Instagram, Facebook, Google, ecc… si preoccupi delle foto che viaggiano verso la Russia distraendosi, anche solo per poco tempo, di quello che fanno le solite multinazionali del digitale; tanto a tenere i nostri dati al “sicuro” ci pensano proprio loro… sempre.
 La nuova moneta che un gruppo capitanato da Facebook si appresta a lanciare si chiamerà Libra ma le diffidenze stanno già crescendo giorno dopo giorno e negli USA
La nuova moneta che un gruppo capitanato da Facebook si appresta a lanciare si chiamerà Libra ma le diffidenze stanno già crescendo giorno dopo giorno e negli USA  La Cina è uno di qui paesi dove la sorveglianza di massa è cosa normalizzata e istituzionalizzata ed è di questi giorni la notizia, data da
La Cina è uno di qui paesi dove la sorveglianza di massa è cosa normalizzata e istituzionalizzata ed è di questi giorni la notizia, data da  Stamattina un’amica mi chiede informazioni su “
Stamattina un’amica mi chiede informazioni su “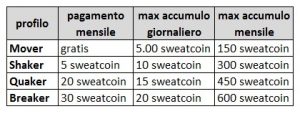








{kind=link}