
Come nasce lo slogan “se è gratis allora il prodotto sei tu” lanciato da Time nel 2010?
Inizialmente dalla consapevolezza che se un’azienda regalava (quella che sembrava) la propria “merce/servizio” voleva dire, ovviamente, che il guadagno stava da un’altra parte.
All’inizio tutti abbiamo pensato che sorbirci la pubblicità, più o meno invadente, per usufruire di un servizio gratis, era il giusto prezzo o il male minore. Eravamo già abituati a quel modello imprenditoriale anni ‘90 proveniente dalle radio e TV private che affollavano i propri programmi di pubblicità e che su internet si traduceva in siti pieni zeppi di banner. Poi un’idea un po’ più precisa ce la siamo fatta quando quella pubblicità è diventata sempre più precisa e sempre più in linea con i nostri desideri. Insomma un sospetto che quel social, quel motore, quel sito di e-commerce ci conoscesse almeno un pochino l’abbiamo avuta. Un sospetto che si è fatto sempre più forte e preoccupante quando i siti hanno iniziato a farsi la lotta a colpi di spazio cloud di servizi on line gratuiti. Si è pure giocato sulla “minaccia del pagamento” per far accrescere i clienti. Vi ricordate le notizie che ciclicamente uscivano sul pagamento di WhatsApp (ma anche di Facebook)? Questa falsa notizia, spinta ad arte, ad ogni tornata raccoglieva qualche milione di utenti in più. Ma non solo, con il passaggio di piattaforma (dal pc allo smartphone) le aziende digitali si sono ritrovati fra le mani una miniera d’oro ricca di dati e senza alcun limite o restrizione. Una sorta di nuova corsa alla conquista del west. In un solo colpo si potevano raccogliere utenti distratti e poco preoccupati della privacy e una quantità di informazioni a cui nessuno avrebbe mai pensato di poter accedere: la rubrica telefonica, la fotocamera, il microfono e tutti i contenuti presenti sull’apparato, anche quelli che apparentemente sembravano non servire a nulla.
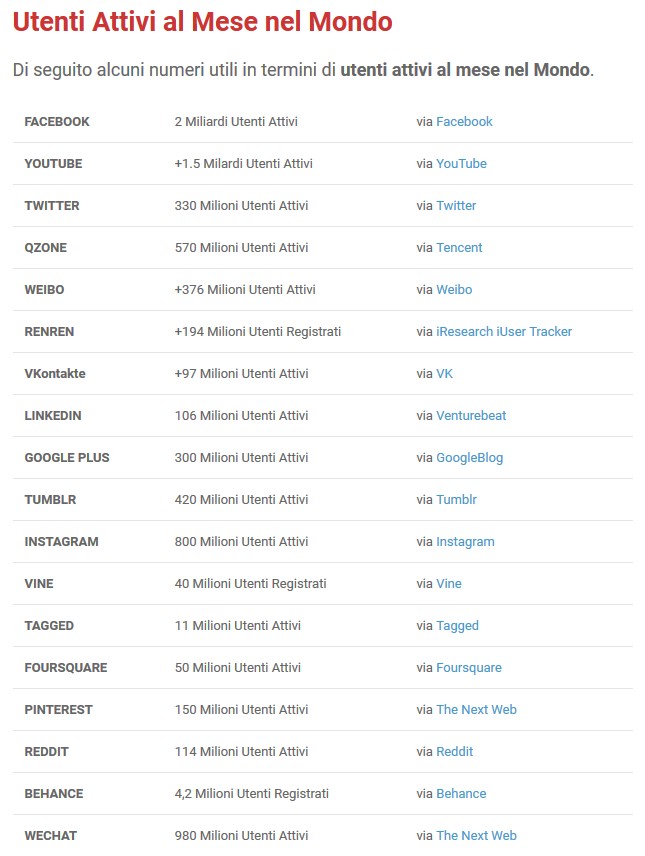
Dalla tabella qui sopra possiamo comprendere l’enormità di dati di cui stiamo parlando; ma se questo numero non vi sembra abbastanza grande, provate a prendere su Facebook, anche soltanto di un mese, le vostre foto, i vostri messaggi (anche quelli privati), le news che avete linkato, i post che avete fatto e i like che avete lasciato, poi moltiplicatelo per 2 miliardi e forse vi farete un’idea approssimativa della quantità di dati che il social immagazzina in un solo mese. Pensate che solo questo semplice calcolo fa valutare 500 miliardi di dollari Facebook in borsa. Poi dovreste ancora moltiplicare per altri software installati sul PC e altrettante App, anche quelle che vi sembrano più innocenti, presenti sullo smartphone ma così, giusto per avere un ordine di grandezza e, vi assicuro, sarete ancora lontani. Questa grandezza numerica forse ci fa comprendere le motivazioni di un’ignavia strisciante che gira intorno e dentro il web e che ha fatto da ammortizzatore anche a bombe come quella di Cambridge Analytica.
Io ero convinto che sarebbero esplosi definitivamente tutti i ragionamenti intorno alla privacy, all’informazione manipolata e tossica e al controllo degli utenti e che in qualche maniera Zuckerberg ne sarebbe uscito malconcio. Ma come dimenticare che nel lontano 2003, quindi in un periodo ancora pre-social-autorappresentativo, aveva avuto problemi simili in tema di violazione della privacy con quella sorta di beta di Facebook, ma non subì alcuna conseguenza, anzi da lì comprese definitivamente qual era la sua merce principale.
La vicenda di Cambridge Analytica non è diventata poco credibile perché intricata o distopica, è solo passata indolore tra le fila degli utenti del social, per via della sua intersecazione al “normale” piano di condivisione e autorappresentazione a cui gli utenti dei social sono abituati e a cui non intendono rinunciare.
Gli utenti di Facebook non sono diminuiti quando si è scoperto che Cambridge Analytica (società vicina alla destra americana) aveva raccolto dati personali per creare profili psicologici degli utenti in modo da lanciare una campagna di marketing elettorale personalizzata a favore di Trump; anche quando si scoprì che la società aveva creato una gran quantità di account fake per diffondevano false notizie su Hillary Clinton; e nemmeno quando Facebook venne accusata di avere reso possibile e facile la raccolta di questi dati e di avere cercato di nascondere il tutto.
Possiamo sfuggire ingannando il sistema? Certo, si può fare ma partire da un account fake e non da quello reale perché se ne andrebbe a farsi benedire la “reputazione on line” e quindi il motivo stesso per il quale si è su quel social.
E comunque, anche se non aderiamo alla filosofia di massa del “non abbiamo nulla da nascondere” e facciamo attenzione alla nostra vita on-line, i social (o la loro somma) raccontano molto, anzi troppo, di noi. Bastano anche solo i like per far parlare le nostre preferenze e i nostri gusti, se poi si mettono in relazione amici, pagine, gruppi, post e condivisioni di notizie, facciamo emergere un profilo molto più preciso, pronto per chi unirà i puntini.
Che i dati siano una merce preziosa non lo dicono i fanatici della privacy ma lo dimostrano i vari attacchi tesi alla “sottrazione dei dati” come quello che è accaduto a Yahoo qualche anno fa.
Insomma i nostri gusti, le nostre ricerche, i nostri acquisti, le nostre letture sono informazioni che consapevolmente produciamo e inconsapevolmente cediamo gratis ad altri che su questo creano profitto.
Ovviamente la questione non riguarda esclusivamente i social o altri faccende legate al web che meglio conosciamo ma anche a una serie di servizi che invece non conosciamo di meno legati ai sistemi di domotica e di geolocalizzazione che vanno dall’accesso remoto alla lavatrice, all’orologio che ci mostra i chilometri e le calorie consumate, alla foto del piatto scattato nel ristorante, alla connessione wi-fi fatta in stazione.
Stiamo parlando di un centinaio di zettabyte di dati di cui non conosciamo quasi nulla, tanto meno chi, come e perchè li sta trattando. Ma tanto agli ignavi del web frega poco, l’importante è condividere l’ultima foto della pappa del bimbo.