Ho già parlato di alcuni software di messaging qui, in riferimento a quelli più diffusi, ma il problema della sicurezza e della privacy degli utenti era e continua a rimanere una piaga aperta su cui i più, purtroppo, buttano semplicemente del sale. Qualsiasi ragionamento facciamo nella direzione della sicurezza/privacy, continua ad albergare all’interno di un’area di approssimazione, più o meno, accettabile.
Ho già parlato di alcuni software di messaging qui, in riferimento a quelli più diffusi, ma il problema della sicurezza e della privacy degli utenti era e continua a rimanere una piaga aperta su cui i più, purtroppo, buttano semplicemente del sale. Qualsiasi ragionamento facciamo nella direzione della sicurezza/privacy, continua ad albergare all’interno di un’area di approssimazione, più o meno, accettabile.
Ora vorrei parlarvi di Jabber (o XMPP – Extensible Messaging and Presence Protocol – che è la stessa cosa) che l’officina ribelle eigenlab di Pisa ha presentato qualche giorno fa. Si tratta di un servizio di messaging open source che gira sul server di una rete XMPP privata (quella di eigenlab appunto) e che permette l’accesso, sicuro e protetto, alla rete XMPP pubblica. Al contrario degli altri software come WhatsApp, Telegram o Signal, XMPP è un protocollo “federato”, nel senso che i client della rete globale dialogano tra loro al di là del server sul quale si sono registrati e quindi entrano in contatto anche con client di reti che utilizzano protocolli differenti (come OSCAR, .NET, ecc…).
Ovviamente esistono client multiprotocollo, ma a differenza di questi, XMPP (acronimo di “protocollo estendibile di messaggistica e presenza”) risolve la cosa già all’accesso del client sul server, poiché ha già messo insieme tutti i protocolli e le tecnologie necessarie, annullando così l’onere di dover programmare un supporto al protocollo a livello di client.
L’idea di Jabber nasce nel 1998 con Jeremie Miller e un gruppo di sviluppatori indipendenti che riescono a sviluppare una rete di instant messaging aperta ed espandibile a qualsiasi altro servizio di messaggistica già esistente. Inoltre la filosofia open source garantì, già da subito, uno sviluppo migliore e un controllo generalizzato sulla sincerità e la bontà della sicurezza dei dati.
Per spiegare l’architettura XMPP, Markus Hofmann e Leland R. Beaumont utilizzano i personaggi “Romeo and Juliet” della tragedia shakespeariana. La metafora racconta che Giulietta e Romeo utilizzano account diversi, appartenenti ciascuno al proprio server familiare. Giulietta, con il proprio account juliet@example.com, invia al suo server un messaggio (Art thou not Romeo and a Montague?) per romeo@example.net; il testo viene ricevuto dal server “example.com” che contatterà il server “example.net” (che ospita l’account di Romeo) e verificata la rispondenza di indirizzo e di linguaggio, si stabilirà una connessione tra i due server recapitando così il messaggio al giusto destinatario che potrà rispondere (Neither, fair saint, if either thee dislike) e così via.
 In sostanza, anche se gli utenti hanno client e sistemi operativi diversi, i server su cui poggiano gli account faranno in modo di portare a buon fine lo scambio comunicativo.
In sostanza, anche se gli utenti hanno client e sistemi operativi diversi, i server su cui poggiano gli account faranno in modo di portare a buon fine lo scambio comunicativo.
E’ quello che si chiama “sistema scalabile”: nessun server centrale che si occupa di smistare i messaggi, ma tanti server che diventano nodi di scambio all’interno della rete XMPP. Questo significa che anche se una parte della rete non funzionasse, quella restante continuerebbe a svolgere egregiamente il proprio compito.
XMPP fornisce sia chat singola che di gruppo, ha una rubrica per i contatti, permette di scambiare file e immagini in chat e stabilisce comunicazioni criptate sia singole che di gruppo.
E’ possibile installare una grande quantità di Clients per qualsiasi tipo di piattaforma e qui trovate tutta la lista. Il migliore per Android è sicuramente Conversations che su Google Play è a pagamento mentre con F-Droid puoi scaricarlo gratis (se volete potete seguire questa guida); mentre per iOS consiglio Monal che trovate gratis sullo store ufficiale.
La sicurezza e la privacy, anche qui, sono affidate a una crittografia end-to-end ed è possibile ricevere messaggi cifrati su più dispositivi, o inviarli anche se il destinatario è offline. La crittografia funziona anche per immagini, file e messaggi vocali. I protocolli crittografici sono implementati in modo trasparente e, grazie allo sviluppo comunitario di questo open source, chiunque può verificare l’assenza di backdoor e di falle di sicurezza nel codice.
Ma per la nostra sicurezza, la domanda giusta è: di chi e di cosa ci fidiamo quando decidiamo di dialogare con qualcuno?
Qualche esempio, un po’ grossolano, sulla nostra percezione (e sulle pratiche) della sicurezza in tema di conversazioni.
La prima cosa che facciamo quando instauriamo una conversazione è quella di capire/decidere, immediatamente, il livello (pubblico, sociale, privato, intimo) a cui tale tipo di comunicazione appartiene. Al netto di disturbi psicologici, sappiamo come discutere in un bar o nella sala d’attesa di un barbiere/parrucchiere, sappiamo (forse un po’ meno) come e cosa scrivere sulla nostra bacheca di Facebook, comprendiamo che per parlare di cose di famiglia è meglio farlo in casa nostra, allo stesso modo ci appartiamo in luoghi e con distanze opportune (curando bene il “canale”) per dialogare di cose intime.
Basandoci su tale paradigma, risolviamo una semplice proporzione che ci da, approssimativamente, il peso della propagazione dell’informazione, in rapporto al numero delle persone presenti nella conversazione. Ovvero, il potenziale di diffusione parte da un numero imprecisato (teoricamente infinito) “x” della conversazione pubblica e arriva fino a “2” nella conversazione intima (ovviamente parliamo di partecipanti e non di rischio diffusione o intercettazione).
Se, dunque, in analogico possiamo assumere come valore minimo teorico di diffusione il numero “2“, in digitale questo valore minimo dev’essere almeno “3” (i due dialoganti/intimi più colui che gestisce il canale). Questo vuol dire almeno due cose: la prima è che non esistere la condizione di “intimità” in una chat; la seconda che, come conseguenza della prima, la nostra soglia di prevenzione della privacy è diventata un po’ più “lasca”.
Ora, possiamo fare tutti i ragionamenti che vogliamo, sulla proprietà, sui sistemi e anche sulla criptazione o qualcos’altro, ma fondamentalmente dobbiamo sempre fidarci di qualcuno che è “altro” rispetto al nostro interlocutore intimo. In sostanza sta a noi scegliere se questo “altro” debba essere Zuckerberg (Messenger, WhatsApp, Instagram), Durov (Telegram), Google (Hangout e Yahoo! Messanger), Microsoft (MSN Messanger e Skype) oppure un’organizzazione no-profit come Open Whisper Systems che gestisce l’open source Signal.
Ecco forse sta proprio qui la chiave di volta: fidarsi di chi non crede che tutti gli scambi debbano essere per forza di natura economica, di chi non venderà i dati appena possibile, di chi non capitalizzerà il successo e di chi da anni si batte per una rete paritaria e democratica.

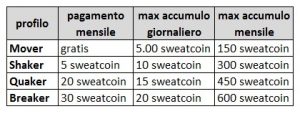
 Stamattina un’amica mi chiede informazioni su “SweatCoin” (letteralmente moneta per il sudore) che è un’app che fa guadagnare dei “punti virtuali” (che molti confondo con i bitcoin ma in realtà non sono soldi virtuali poiché non si tratta di una criptovaluta su tecnologie blockchain) con i quali poter acquistare dei prodotti all’interno dei negozi legati alla piattaforma.
Stamattina un’amica mi chiede informazioni su “SweatCoin” (letteralmente moneta per il sudore) che è un’app che fa guadagnare dei “punti virtuali” (che molti confondo con i bitcoin ma in realtà non sono soldi virtuali poiché non si tratta di una criptovaluta su tecnologie blockchain) con i quali poter acquistare dei prodotti all’interno dei negozi legati alla piattaforma.